Processes time-varying inputs using a simple recurrent neural network (RNN). Implemented as a network unrolling the RNN computation in time. More...
#include <rnn_layer.hpp>
Inheritance diagram for caffe::RNNLayer< Dtype >:
Public Member Functions | |
| RNNLayer (const LayerParameter ¶m) | |
| virtual const char * | type () const |
| Returns the layer type. | |
 Public Member Functions inherited from caffe::RecurrentLayer< Dtype > Public Member Functions inherited from caffe::RecurrentLayer< Dtype > | |
| RecurrentLayer (const LayerParameter ¶m) | |
| virtual void | LayerSetUp (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| Does layer-specific setup: your layer should implement this function as well as Reshape. More... | |
| virtual void | Reshape (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| Adjust the shapes of top blobs and internal buffers to accommodate the shapes of the bottom blobs. More... | |
| virtual void | Reset () |
| virtual int | MinBottomBlobs () const |
| Returns the minimum number of bottom blobs required by the layer, or -1 if no minimum number is required. More... | |
| virtual int | MaxBottomBlobs () const |
| Returns the maximum number of bottom blobs required by the layer, or -1 if no maximum number is required. More... | |
| virtual int | ExactNumTopBlobs () const |
| Returns the exact number of top blobs required by the layer, or -1 if no exact number is required. More... | |
| virtual bool | AllowForceBackward (const int bottom_index) const |
| Return whether to allow force_backward for a given bottom blob index. More... | |
| Public Member Functions inherited from caffe::Layer< Dtype > | |
| Layer (const LayerParameter ¶m) | |
| void | SetUp (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| Implements common layer setup functionality. More... | |
| Dtype | Forward (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| Given the bottom blobs, compute the top blobs and the loss. More... | |
| void | Backward (const vector< Blob< Dtype > *> &top, const vector< bool > &propagate_down, const vector< Blob< Dtype > *> &bottom) |
| Given the top blob error gradients, compute the bottom blob error gradients. More... | |
| vector< shared_ptr< Blob< Dtype > > > & | blobs () |
| Returns the vector of learnable parameter blobs. | |
| const LayerParameter & | layer_param () const |
| Returns the layer parameter. | |
| virtual void | ToProto (LayerParameter *param, bool write_diff=false) |
| Writes the layer parameter to a protocol buffer. | |
| Dtype | loss (const int top_index) const |
| Returns the scalar loss associated with a top blob at a given index. | |
| void | set_loss (const int top_index, const Dtype value) |
| Sets the loss associated with a top blob at a given index. | |
| virtual int | ExactNumBottomBlobs () const |
| Returns the exact number of bottom blobs required by the layer, or -1 if no exact number is required. More... | |
| virtual int | MinTopBlobs () const |
| Returns the minimum number of top blobs required by the layer, or -1 if no minimum number is required. More... | |
| virtual int | MaxTopBlobs () const |
| Returns the maximum number of top blobs required by the layer, or -1 if no maximum number is required. More... | |
| virtual bool | EqualNumBottomTopBlobs () const |
| Returns true if the layer requires an equal number of bottom and top blobs. More... | |
| virtual bool | AutoTopBlobs () const |
| Return whether "anonymous" top blobs are created automatically by the layer. More... | |
| bool | param_propagate_down (const int param_id) |
| Specifies whether the layer should compute gradients w.r.t. a parameter at a particular index given by param_id. More... | |
| void | set_param_propagate_down (const int param_id, const bool value) |
| Sets whether the layer should compute gradients w.r.t. a parameter at a particular index given by param_id. | |
Protected Member Functions | |
| virtual void | FillUnrolledNet (NetParameter *net_param) const |
| Fills net_param with the recurrent network architecture. Subclasses should define this – see RNNLayer and LSTMLayer for examples. | |
| virtual void | RecurrentInputBlobNames (vector< string > *names) const |
| Fills names with the names of the 0th timestep recurrent input Blob&s. Subclasses should define this – see RNNLayer and LSTMLayer for examples. | |
| virtual void | RecurrentOutputBlobNames (vector< string > *names) const |
| Fills names with the names of the Tth timestep recurrent output Blob&s. Subclasses should define this – see RNNLayer and LSTMLayer for examples. | |
| virtual void | RecurrentInputShapes (vector< BlobShape > *shapes) const |
| Fills shapes with the shapes of the recurrent input Blob&s. Subclasses should define this – see RNNLayer and LSTMLayer for examples. | |
| virtual void | OutputBlobNames (vector< string > *names) const |
| Fills names with the names of the output blobs, concatenated across all timesteps. Should return a name for each top Blob. Subclasses should define this – see RNNLayer and LSTMLayer for examples. | |
| Protected Member Functions inherited from caffe::RecurrentLayer< Dtype > | |
| virtual void | Forward_cpu (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| virtual void | Forward_gpu (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| Using the GPU device, compute the layer output. Fall back to Forward_cpu() if unavailable. | |
| virtual void | Backward_cpu (const vector< Blob< Dtype > *> &top, const vector< bool > &propagate_down, const vector< Blob< Dtype > *> &bottom) |
| Using the CPU device, compute the gradients for any parameters and for the bottom blobs if propagate_down is true. | |
| Protected Member Functions inherited from caffe::Layer< Dtype > | |
| virtual void | Backward_gpu (const vector< Blob< Dtype > *> &top, const vector< bool > &propagate_down, const vector< Blob< Dtype > *> &bottom) |
| Using the GPU device, compute the gradients for any parameters and for the bottom blobs if propagate_down is true. Fall back to Backward_cpu() if unavailable. | |
| virtual void | CheckBlobCounts (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| void | SetLossWeights (const vector< Blob< Dtype > *> &top) |
Additional Inherited Members | |
| Protected Attributes inherited from caffe::RecurrentLayer< Dtype > | |
| shared_ptr< Net< Dtype > > | unrolled_net_ |
| A Net to implement the Recurrent functionality. | |
| int | N_ |
| The number of independent streams to process simultaneously. | |
| int | T_ |
| The number of timesteps in the layer's input, and the number of timesteps over which to backpropagate through time. | |
| bool | static_input_ |
| Whether the layer has a "static" input copied across all timesteps. | |
| int | last_layer_index_ |
| The last layer to run in the network. (Any later layers are losses added to force the recurrent net to do backprop.) | |
| bool | expose_hidden_ |
| Whether the layer's hidden state at the first and last timesteps are layer inputs and outputs, respectively. | |
| vector< Blob< Dtype > *> | recur_input_blobs_ |
| vector< Blob< Dtype > *> | recur_output_blobs_ |
| vector< Blob< Dtype > *> | output_blobs_ |
| Blob< Dtype > * | x_input_blob_ |
| Blob< Dtype > * | x_static_input_blob_ |
| Blob< Dtype > * | cont_input_blob_ |
| Protected Attributes inherited from caffe::Layer< Dtype > | |
| LayerParameter | layer_param_ |
| Phase | phase_ |
| vector< shared_ptr< Blob< Dtype > > > | blobs_ |
| vector< bool > | param_propagate_down_ |
| vector< Dtype > | loss_ |
Detailed Description
template<typename Dtype>
class caffe::RNNLayer< Dtype >
Processes time-varying inputs using a simple recurrent neural network (RNN). Implemented as a network unrolling the RNN computation in time.
Given time-varying inputs 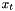 , computes hidden state
, computes hidden state ![$ h_t := \tanh[ W_{hh} h_{t_1} + W_{xh} x_t + b_h ] $](form_157.png) , and outputs
, and outputs ![$ o_t := \tanh[ W_{ho} h_t + b_o ] $](form_158.png) .
.
The documentation for this class was generated from the following files:
- include/caffe/layers/rnn_layer.hpp
- src/caffe/layers/rnn_layer.cpp
