A layer factory that allows one to register layers. During runtime, registered layers can be called by passing a LayerParameter protobuffer to the CreateLayer function: More...
Namespaces | |
| SolverAction | |
| Enumeration of actions that a client of the Solver may request by implementing the Solver's action request function, which a client may optionally provide in order to request early termination or saving a snapshot without exiting. In the executable caffe, this mechanism is used to allow the snapshot to be saved when stopping execution with a SIGINT (Ctrl-C). | |
Classes | |
| class | AbsValLayer |
Computes 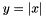 . More... . More... | |
| class | AccuracyLayer |
| Computes the classification accuracy for a one-of-many classification task. More... | |
| class | AdaDeltaSolver |
| class | AdaGradSolver |
| class | AdamSolver |
| AdamSolver, an algorithm for first-order gradient-based optimization of stochastic objective functions, based on adaptive estimates of lower-order moments. Described in [1]. More... | |
| class | ArgMaxLayer |
Compute the index of the  max values for each datum across all dimensions max values for each datum across all dimensions  . More... . More... | |
| class | BaseConvolutionLayer |
| Abstract base class that factors out the BLAS code common to ConvolutionLayer and DeconvolutionLayer. More... | |
| class | BaseDataLayer |
| Provides base for data layers that feed blobs to the Net. More... | |
| class | BasePrefetchingDataLayer |
| class | Batch |
| class | BatchNormLayer |
| Normalizes the input to have 0-mean and/or unit (1) variance across the batch. More... | |
| class | BatchReindexLayer |
| Index into the input blob along its first axis. More... | |
| class | BiasLayer |
| Computes a sum of two input Blobs, with the shape of the latter Blob "broadcast" to match the shape of the former. Equivalent to tiling the latter Blob, then computing the elementwise sum. More... | |
| class | BilinearFiller |
| Fills a Blob with coefficients for bilinear interpolation. More... | |
| class | Blob |
| A wrapper around SyncedMemory holders serving as the basic computational unit through which Layers, Nets, and Solvers interact. More... | |
| class | BlockingQueue |
| class | BNLLLayer |
Computes 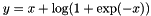 if if 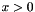 ; ; 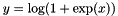 otherwise. More... otherwise. More... | |
| class | Caffe |
| class | ConcatLayer |
| Takes at least two Blobs and concatenates them along either the num or channel dimension, outputting the result. More... | |
| class | ConstantFiller |
Fills a Blob with constant values 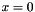 . More... . More... | |
| class | ContrastiveLossLayer |
Computes the contrastive loss 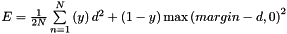 where where 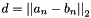 . This can be used to train siamese networks. More... . This can be used to train siamese networks. More... | |
| class | ConvolutionLayer |
| Convolves the input image with a bank of learned filters, and (optionally) adds biases. More... | |
| class | CPUTimer |
| class | CropLayer |
| Takes a Blob and crop it, to the shape specified by the second input Blob, across all dimensions after the specified axis. More... | |
| class | DataLayer |
| class | DataTransformer |
| Applies common transformations to the input data, such as scaling, mirroring, substracting the image mean... More... | |
| class | DeconvolutionLayer |
| Convolve the input with a bank of learned filters, and (optionally) add biases, treating filters and convolution parameters in the opposite sense as ConvolutionLayer. More... | |
| class | DropoutLayer |
During training only, sets a random portion of 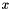 to 0, adjusting the rest of the vector magnitude accordingly. More... to 0, adjusting the rest of the vector magnitude accordingly. More... | |
| class | DummyDataLayer |
| Provides data to the Net generated by a Filler. More... | |
| class | EltwiseLayer |
| Compute elementwise operations, such as product and sum, along multiple input Blobs. More... | |
| class | ELULayer |
Exponential Linear Unit non-linearity 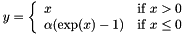 . More... . More... | |
| class | EmbedLayer |
| A layer for learning "embeddings" of one-hot vector input. Equivalent to an InnerProductLayer with one-hot vectors as input, but for efficiency the input is the "hot" index of each column itself. More... | |
| class | EuclideanLossLayer |
Computes the Euclidean (L2) loss 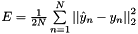 for real-valued regression tasks. More... for real-valued regression tasks. More... | |
| class | ExpLayer |
Computes 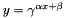 , as specified by the scale , as specified by the scale 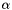 , shift , shift 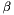 , and base , and base 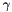 . More... . More... | |
| class | Filler |
| Fills a Blob with constant or randomly-generated data. More... | |
| class | FilterLayer |
| Takes two+ Blobs, interprets last Blob as a selector and filter remaining Blobs accordingly with selector data (0 means that the corresponding item has to be filtered, non-zero means that corresponding item needs to stay). More... | |
| class | FlattenLayer |
| Reshapes the input Blob into flat vectors. More... | |
| class | GaussianFiller |
Fills a Blob with Gaussian-distributed values 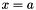 . More... . More... | |
| class | HDF5DataLayer |
| Provides data to the Net from HDF5 files. More... | |
| class | HDF5OutputLayer |
| Write blobs to disk as HDF5 files. More... | |
| class | HingeLossLayer |
| Computes the hinge loss for a one-of-many classification task. More... | |
| class | Im2colLayer |
| A helper for image operations that rearranges image regions into column vectors. Used by ConvolutionLayer to perform convolution by matrix multiplication. More... | |
| class | ImageDataLayer |
| Provides data to the Net from image files. More... | |
| class | InfogainLossLayer |
| A generalization of MultinomialLogisticLossLayer that takes an "information gain" (infogain) matrix specifying the "value" of all label pairs. More... | |
| class | InnerProductLayer |
| Also known as a "fully-connected" layer, computes an inner product with a set of learned weights, and (optionally) adds biases. More... | |
| class | InputLayer |
| Provides data to the Net by assigning tops directly. More... | |
| class | InternalThread |
| class | Layer |
| An interface for the units of computation which can be composed into a Net. More... | |
| class | LayerRegisterer |
| class | LayerRegistry |
| class | LogLayer |
Computes 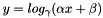 , as specified by the scale , shift , and base . More... , as specified by the scale , shift , and base . More... | |
| class | LossLayer |
| An interface for Layers that take two Blobs as input – usually (1) predictions and (2) ground-truth labels – and output a singleton Blob representing the loss. More... | |
| class | LRNLayer |
| Normalize the input in a local region across or within feature maps. More... | |
| class | LSTMLayer |
| Processes sequential inputs using a "Long Short-Term Memory" (LSTM) [1] style recurrent neural network (RNN). Implemented by unrolling the LSTM computation through time. More... | |
| class | LSTMUnitLayer |
| A helper for LSTMLayer: computes a single timestep of the non-linearity of the LSTM, producing the updated cell and hidden states. More... | |
| class | MemoryDataLayer |
| Provides data to the Net from memory. More... | |
| class | MSRAFiller |
Fills a Blob with values 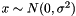 where where 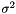 is set inversely proportional to number of incoming nodes, outgoing nodes, or their average. More... is set inversely proportional to number of incoming nodes, outgoing nodes, or their average. More... | |
| class | MultinomialLogisticLossLayer |
| Computes the multinomial logistic loss for a one-of-many classification task, directly taking a predicted probability distribution as input. More... | |
| class | MVNLayer |
| Normalizes the input to have 0-mean and/or unit (1) variance. More... | |
| class | NesterovSolver |
| class | Net |
| Connects Layers together into a directed acyclic graph (DAG) specified by a NetParameter. More... | |
| class | NeuronLayer |
An interface for layers that take one blob as input ( 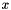 ) and produce one equally-sized blob as output ( ) and produce one equally-sized blob as output ( 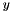 ), where each element of the output depends only on the corresponding input element. More... ), where each element of the output depends only on the corresponding input element. More... | |
| class | ParameterLayer |
| class | PoolingLayer |
| Pools the input image by taking the max, average, etc. within regions. More... | |
| class | PositiveUnitballFiller |
Fills a Blob with values ![$ x \in [0, 1] $](form_3.png) such that such that 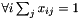 . More... . More... | |
| class | PowerLayer |
Computes 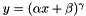 , as specified by the scale , shift , and power . More... , as specified by the scale , shift , and power . More... | |
| class | PReLULayer |
Parameterized Rectified Linear Unit non-linearity 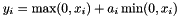 . The differences from ReLULayer are 1) negative slopes are learnable though backprop and 2) negative slopes can vary across channels. The number of axes of input blob should be greater than or equal to 2. The 1st axis (0-based) is seen as channels. More... . The differences from ReLULayer are 1) negative slopes are learnable though backprop and 2) negative slopes can vary across channels. The number of axes of input blob should be greater than or equal to 2. The 1st axis (0-based) is seen as channels. More... | |
| class | PythonLayer |
| class | RecurrentLayer |
| An abstract class for implementing recurrent behavior inside of an unrolled network. This Layer type cannot be instantiated – instead, you should use one of its implementations which defines the recurrent architecture, such as RNNLayer or LSTMLayer. More... | |
| class | ReductionLayer |
| Compute "reductions" – operations that return a scalar output Blob for an input Blob of arbitrary size, such as the sum, absolute sum, and sum of squares. More... | |
| class | ReLULayer |
Rectified Linear Unit non-linearity 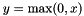 . The simple max is fast to compute, and the function does not saturate. More... . The simple max is fast to compute, and the function does not saturate. More... | |
| class | ReshapeLayer |
| class | RMSPropSolver |
| class | RNNLayer |
| Processes time-varying inputs using a simple recurrent neural network (RNN). Implemented as a network unrolling the RNN computation in time. More... | |
| class | ScaleLayer |
Computes the elementwise product of two input Blobs, with the shape of the latter Blob "broadcast" to match the shape of the former. Equivalent to tiling the latter Blob, then computing the elementwise product. Note: for efficiency and convenience, this layer can additionally perform a "broadcast" sum too when bias_term: true is set. More... | |
| class | SGDSolver |
| Optimizes the parameters of a Net using stochastic gradient descent (SGD) with momentum. More... | |
| class | SigmoidCrossEntropyLossLayer |
Computes the cross-entropy (logistic) loss ![$ E = \frac{-1}{n} \sum\limits_{n=1}^N \left[ p_n \log \hat{p}_n + (1 - p_n) \log(1 - \hat{p}_n) \right] $](form_163.png) , often used for predicting targets interpreted as probabilities. More... , often used for predicting targets interpreted as probabilities. More... | |
| class | SigmoidLayer |
Sigmoid function non-linearity 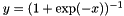 , a classic choice in neural networks. More... , a classic choice in neural networks. More... | |
| class | SignalHandler |
| class | SilenceLayer |
| Ignores bottom blobs while producing no top blobs. (This is useful to suppress outputs during testing.) More... | |
| class | SliceLayer |
| Takes a Blob and slices it along either the num or channel dimension, outputting multiple sliced Blob results. More... | |
| class | SoftmaxLayer |
| Computes the softmax function. More... | |
| class | SoftmaxWithLossLayer |
| Computes the multinomial logistic loss for a one-of-many classification task, passing real-valued predictions through a softmax to get a probability distribution over classes. More... | |
| class | Solver |
| An interface for classes that perform optimization on Nets. More... | |
| class | SolverRegisterer |
| class | SolverRegistry |
| class | SplitLayer |
| Creates a "split" path in the network by copying the bottom Blob into multiple top Blobs to be used by multiple consuming layers. More... | |
| class | SPPLayer |
| Does spatial pyramid pooling on the input image by taking the max, average, etc. within regions so that the result vector of different sized images are of the same size. More... | |
| class | SyncedMemory |
| Manages memory allocation and synchronization between the host (CPU) and device (GPU). More... | |
| class | TanHLayer |
TanH hyperbolic tangent non-linearity 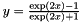 , popular in auto-encoders. More... , popular in auto-encoders. More... | |
| class | ThresholdLayer |
| Tests whether the input exceeds a threshold: outputs 1 for inputs above threshold; 0 otherwise. More... | |
| class | TileLayer |
| Copy a Blob along specified dimensions. More... | |
| class | Timer |
| class | UniformFiller |
Fills a Blob with uniformly distributed values 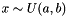 . More... . More... | |
| class | WindowDataLayer |
| Provides data to the Net from windows of images files, specified by a window data file. This layer is DEPRECATED and only kept for archival purposes for use by the original R-CNN. More... | |
| class | XavierFiller |
Fills a Blob with values 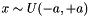 where where 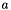 is set inversely proportional to number of incoming nodes, outgoing nodes, or their average. More... is set inversely proportional to number of incoming nodes, outgoing nodes, or their average. More... | |
Typedefs | |
| typedef boost::function< SolverAction::Enum()> | ActionCallback |
| Type of a function that returns a Solver Action enumeration. | |
| typedef boost::mt19937 | rng_t |
Functions | |
| void | GlobalInit (int *pargc, char ***pargv) |
| template<typename Dtype > | |
| Filler< Dtype > * | GetFiller (const FillerParameter ¶m) |
| Get a specific filler from the specification given in FillerParameter. More... | |
| void | CaffeMallocHost (void **ptr, size_t size, bool *use_cuda) |
| void | CaffeFreeHost (void *ptr, bool use_cuda) |
| const char * | cublasGetErrorString (cublasStatus_t error) |
| const char * | curandGetErrorString (curandStatus_t error) |
| int | CAFFE_GET_BLOCKS (const int N) |
| std::string | format_int (int n, int numberOfLeadingZeros=0) |
| template<typename Dtype > | |
| void | hdf5_load_nd_dataset_helper (hid_t file_id, const char *dataset_name_, int min_dim, int max_dim, Blob< Dtype > *blob, bool reshape) |
| template<typename Dtype > | |
| void | hdf5_load_nd_dataset (hid_t file_id, const char *dataset_name_, int min_dim, int max_dim, Blob< Dtype > *blob, bool reshape=false) |
| template<typename Dtype > | |
| void | hdf5_save_nd_dataset (const hid_t file_id, const string &dataset_name, const Blob< Dtype > &blob, bool write_diff=false) |
| int | hdf5_load_int (hid_t loc_id, const string &dataset_name) |
| void | hdf5_save_int (hid_t loc_id, const string &dataset_name, int i) |
| string | hdf5_load_string (hid_t loc_id, const string &dataset_name) |
| void | hdf5_save_string (hid_t loc_id, const string &dataset_name, const string &s) |
| int | hdf5_get_num_links (hid_t loc_id) |
| string | hdf5_get_name_by_idx (hid_t loc_id, int idx) |
| template<typename Dtype > | |
| void | im2col_nd_cpu (const Dtype *data_im, const int num_spatial_axes, const int *im_shape, const int *col_shape, const int *kernel_shape, const int *pad, const int *stride, const int *dilation, Dtype *data_col) |
| template<typename Dtype > | |
| void | im2col_cpu (const Dtype *data_im, const int channels, const int height, const int width, const int kernel_h, const int kernel_w, const int pad_h, const int pad_w, const int stride_h, const int stride_w, const int dilation_h, const int dilation_w, Dtype *data_col) |
| template<typename Dtype > | |
| void | col2im_nd_cpu (const Dtype *data_col, const int num_spatial_axes, const int *im_shape, const int *col_shape, const int *kernel_shape, const int *pad, const int *stride, const int *dilation, Dtype *data_im) |
| template<typename Dtype > | |
| void | col2im_cpu (const Dtype *data_col, const int channels, const int height, const int width, const int kernel_h, const int kernel_w, const int pad_h, const int pad_w, const int stride_h, const int stride_w, const int dilation_h, const int dilation_w, Dtype *data_im) |
| template<typename Dtype > | |
| void | im2col_nd_gpu (const Dtype *data_im, const int num_spatial_axes, const int col_size, const int *im_shape, const int *col_shape, const int *kernel_shape, const int *pad, const int *stride, const int *dilation, Dtype *data_col) |
| template<typename Dtype > | |
| void | im2col_gpu (const Dtype *data_im, const int channels, const int height, const int width, const int kernel_h, const int kernel_w, const int pad_h, const int pad_w, const int stride_h, const int stride_w, const int dilation_h, const int dilation_w, Dtype *data_col) |
| template<typename Dtype > | |
| void | col2im_nd_gpu (const Dtype *data_col, const int num_spatial_axes, const int im_size, const int *im_shape, const int *col_shape, const int *kernel_shape, const int *pad, const int *stride, const int *dilation, Dtype *data_im) |
| template<typename Dtype > | |
| void | col2im_gpu (const Dtype *data_col, const int channels, const int height, const int width, const int kernel_h, const int kernel_w, const int pad_h, const int pad_w, const int stride_h, const int stride_w, const int dilation_h, const int dilation_w, Dtype *data_im) |
| void | InsertSplits (const NetParameter ¶m, NetParameter *param_split) |
| void | ConfigureSplitLayer (const string &layer_name, const string &blob_name, const int blob_idx, const int split_count, const float loss_weight, LayerParameter *split_layer_param) |
| string | SplitLayerName (const string &layer_name, const string &blob_name, const int blob_idx) |
| string | SplitBlobName (const string &layer_name, const string &blob_name, const int blob_idx, const int split_idx) |
| void | MakeTempDir (string *temp_dirname) |
| void | MakeTempFilename (string *temp_filename) |
| bool | ReadProtoFromTextFile (const char *filename, Message *proto) |
| bool | ReadProtoFromTextFile (const string &filename, Message *proto) |
| void | ReadProtoFromTextFileOrDie (const char *filename, Message *proto) |
| void | ReadProtoFromTextFileOrDie (const string &filename, Message *proto) |
| void | WriteProtoToTextFile (const Message &proto, const char *filename) |
| void | WriteProtoToTextFile (const Message &proto, const string &filename) |
| bool | ReadProtoFromBinaryFile (const char *filename, Message *proto) |
| bool | ReadProtoFromBinaryFile (const string &filename, Message *proto) |
| void | ReadProtoFromBinaryFileOrDie (const char *filename, Message *proto) |
| void | ReadProtoFromBinaryFileOrDie (const string &filename, Message *proto) |
| void | WriteProtoToBinaryFile (const Message &proto, const char *filename) |
| void | WriteProtoToBinaryFile (const Message &proto, const string &filename) |
| bool | ReadFileToDatum (const string &filename, const int label, Datum *datum) |
| bool | ReadFileToDatum (const string &filename, Datum *datum) |
| bool | ReadImageToDatum (const string &filename, const int label, const int height, const int width, const bool is_color, const std::string &encoding, Datum *datum) |
| bool | ReadImageToDatum (const string &filename, const int label, const int height, const int width, const bool is_color, Datum *datum) |
| bool | ReadImageToDatum (const string &filename, const int label, const int height, const int width, Datum *datum) |
| bool | ReadImageToDatum (const string &filename, const int label, const bool is_color, Datum *datum) |
| bool | ReadImageToDatum (const string &filename, const int label, Datum *datum) |
| bool | ReadImageToDatum (const string &filename, const int label, const std::string &encoding, Datum *datum) |
| bool | DecodeDatumNative (Datum *datum) |
| bool | DecodeDatum (Datum *datum, bool is_color) |
| template<typename Dtype > | |
| void | caffe_cpu_gemm (const CBLAS_TRANSPOSE TransA, const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K, const Dtype alpha, const Dtype *A, const Dtype *B, const Dtype beta, Dtype *C) |
| template<typename Dtype > | |
| void | caffe_cpu_gemv (const CBLAS_TRANSPOSE TransA, const int M, const int N, const Dtype alpha, const Dtype *A, const Dtype *x, const Dtype beta, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_axpy (const int N, const Dtype alpha, const Dtype *X, Dtype *Y) |
| template<typename Dtype > | |
| void | caffe_cpu_axpby (const int N, const Dtype alpha, const Dtype *X, const Dtype beta, Dtype *Y) |
| template<typename Dtype > | |
| void | caffe_copy (const int N, const Dtype *X, Dtype *Y) |
| template<typename Dtype > | |
| void | caffe_set (const int N, const Dtype alpha, Dtype *X) |
| void | caffe_memset (const size_t N, const int alpha, void *X) |
| template<typename Dtype > | |
| void | caffe_add_scalar (const int N, const Dtype alpha, Dtype *X) |
| template<typename Dtype > | |
| void | caffe_scal (const int N, const Dtype alpha, Dtype *X) |
| template<typename Dtype > | |
| void | caffe_sqr (const int N, const Dtype *a, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_sqrt (const int N, const Dtype *a, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_add (const int N, const Dtype *a, const Dtype *b, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_sub (const int N, const Dtype *a, const Dtype *b, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_mul (const int N, const Dtype *a, const Dtype *b, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_div (const int N, const Dtype *a, const Dtype *b, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_powx (const int n, const Dtype *a, const Dtype b, Dtype *y) |
| unsigned int | caffe_rng_rand () |
| template<typename Dtype > | |
| Dtype | caffe_nextafter (const Dtype b) |
| template<typename Dtype > | |
| void | caffe_rng_uniform (const int n, const Dtype a, const Dtype b, Dtype *r) |
| template<typename Dtype > | |
| void | caffe_rng_gaussian (const int n, const Dtype mu, const Dtype sigma, Dtype *r) |
| template<typename Dtype > | |
| void | caffe_rng_bernoulli (const int n, const Dtype p, int *r) |
| template<typename Dtype > | |
| void | caffe_rng_bernoulli (const int n, const Dtype p, unsigned int *r) |
| template<typename Dtype > | |
| void | caffe_exp (const int n, const Dtype *a, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_log (const int n, const Dtype *a, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_abs (const int n, const Dtype *a, Dtype *y) |
| template<typename Dtype > | |
| Dtype | caffe_cpu_dot (const int n, const Dtype *x, const Dtype *y) |
| template<typename Dtype > | |
| Dtype | caffe_cpu_strided_dot (const int n, const Dtype *x, const int incx, const Dtype *y, const int incy) |
| template<typename Dtype > | |
| Dtype | caffe_cpu_asum (const int n, const Dtype *x) |
| template<typename Dtype > | |
| int8_t | caffe_sign (Dtype val) |
| DEFINE_CAFFE_CPU_UNARY_FUNC (sgnbit, y[i]=static_cast< bool >((std::signbit)(x[i]))) template< typename Dtype > void caffe_cpu_scale(const int n | |
| template<typename Dtype > | |
| void | caffe_gpu_gemm (const CBLAS_TRANSPOSE TransA, const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K, const Dtype alpha, const Dtype *A, const Dtype *B, const Dtype beta, Dtype *C) |
| template<typename Dtype > | |
| void | caffe_gpu_gemv (const CBLAS_TRANSPOSE TransA, const int M, const int N, const Dtype alpha, const Dtype *A, const Dtype *x, const Dtype beta, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_axpy (const int N, const Dtype alpha, const Dtype *X, Dtype *Y) |
| template<typename Dtype > | |
| void | caffe_gpu_axpby (const int N, const Dtype alpha, const Dtype *X, const Dtype beta, Dtype *Y) |
| void | caffe_gpu_memcpy (const size_t N, const void *X, void *Y) |
| template<typename Dtype > | |
| void | caffe_gpu_set (const int N, const Dtype alpha, Dtype *X) |
| void | caffe_gpu_memset (const size_t N, const int alpha, void *X) |
| template<typename Dtype > | |
| void | caffe_gpu_add_scalar (const int N, const Dtype alpha, Dtype *X) |
| template<typename Dtype > | |
| void | caffe_gpu_scal (const int N, const Dtype alpha, Dtype *X) |
| template<typename Dtype > | |
| void | caffe_gpu_scal (const int N, const Dtype alpha, Dtype *X, cudaStream_t str) |
| template<typename Dtype > | |
| void | caffe_gpu_add (const int N, const Dtype *a, const Dtype *b, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_sub (const int N, const Dtype *a, const Dtype *b, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_mul (const int N, const Dtype *a, const Dtype *b, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_div (const int N, const Dtype *a, const Dtype *b, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_abs (const int n, const Dtype *a, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_exp (const int n, const Dtype *a, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_log (const int n, const Dtype *a, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_powx (const int n, const Dtype *a, const Dtype b, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_sqrt (const int n, const Dtype *a, Dtype *y) |
| void | caffe_gpu_rng_uniform (const int n, unsigned int *r) |
| template<typename Dtype > | |
| void | caffe_gpu_rng_uniform (const int n, const Dtype a, const Dtype b, Dtype *r) |
| template<typename Dtype > | |
| void | caffe_gpu_rng_gaussian (const int n, const Dtype mu, const Dtype sigma, Dtype *r) |
| template<typename Dtype > | |
| void | caffe_gpu_rng_bernoulli (const int n, const Dtype p, int *r) |
| template<typename Dtype > | |
| void | caffe_gpu_dot (const int n, const Dtype *x, const Dtype *y, Dtype *out) |
| template<typename Dtype > | |
| void | caffe_gpu_asum (const int n, const Dtype *x, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_sign (const int n, const Dtype *x, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_sgnbit (const int n, const Dtype *x, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_fabs (const int n, const Dtype *x, Dtype *y) |
| template<typename Dtype > | |
| void | caffe_gpu_scale (const int n, const Dtype alpha, const Dtype *x, Dtype *y) |
| rng_t * | caffe_rng () |
| template<class RandomAccessIterator , class RandomGenerator > | |
| void | shuffle (RandomAccessIterator begin, RandomAccessIterator end, RandomGenerator *gen) |
| template<class RandomAccessIterator > | |
| void | shuffle (RandomAccessIterator begin, RandomAccessIterator end) |
| bool | NetNeedsUpgrade (const NetParameter &net_param) |
| bool | UpgradeNetAsNeeded (const string ¶m_file, NetParameter *param) |
| void | ReadNetParamsFromTextFileOrDie (const string ¶m_file, NetParameter *param) |
| void | ReadNetParamsFromBinaryFileOrDie (const string ¶m_file, NetParameter *param) |
| bool | NetNeedsV0ToV1Upgrade (const NetParameter &net_param) |
| bool | UpgradeV0Net (const NetParameter &v0_net_param, NetParameter *net_param) |
| void | UpgradeV0PaddingLayers (const NetParameter ¶m, NetParameter *param_upgraded_pad) |
| bool | UpgradeV0LayerParameter (const V1LayerParameter &v0_layer_connection, V1LayerParameter *layer_param) |
| V1LayerParameter_LayerType | UpgradeV0LayerType (const string &type) |
| bool | NetNeedsDataUpgrade (const NetParameter &net_param) |
| void | UpgradeNetDataTransformation (NetParameter *net_param) |
| bool | NetNeedsV1ToV2Upgrade (const NetParameter &net_param) |
| bool | UpgradeV1Net (const NetParameter &v1_net_param, NetParameter *net_param) |
| bool | UpgradeV1LayerParameter (const V1LayerParameter &v1_layer_param, LayerParameter *layer_param) |
| const char * | UpgradeV1LayerType (const V1LayerParameter_LayerType type) |
| bool | NetNeedsInputUpgrade (const NetParameter &net_param) |
| void | UpgradeNetInput (NetParameter *net_param) |
| bool | NetNeedsBatchNormUpgrade (const NetParameter &net_param) |
| void | UpgradeNetBatchNorm (NetParameter *net_param) |
| bool | SolverNeedsTypeUpgrade (const SolverParameter &solver_param) |
| bool | UpgradeSolverType (SolverParameter *solver_param) |
| bool | UpgradeSolverAsNeeded (const string ¶m_file, SolverParameter *param) |
| void | ReadSolverParamsFromTextFileOrDie (const string ¶m_file, SolverParameter *param) |
| INSTANTIATE_CLASS (Blob) | |
| int64_t | cluster_seedgen (void) |
| INSTANTIATE_CLASS (DataTransformer) | |
| INSTANTIATE_CLASS (Layer) | |
| template<typename Dtype > | |
| shared_ptr< Layer< Dtype > > | GetConvolutionLayer (const LayerParameter ¶m) |
| REGISTER_LAYER_CREATOR (Convolution, GetConvolutionLayer) | |
| template<typename Dtype > | |
| shared_ptr< Layer< Dtype > > | GetPoolingLayer (const LayerParameter ¶m) |
| REGISTER_LAYER_CREATOR (Pooling, GetPoolingLayer) | |
| template<typename Dtype > | |
| shared_ptr< Layer< Dtype > > | GetLRNLayer (const LayerParameter ¶m) |
| REGISTER_LAYER_CREATOR (LRN, GetLRNLayer) | |
| template<typename Dtype > | |
| shared_ptr< Layer< Dtype > > | GetReLULayer (const LayerParameter ¶m) |
| REGISTER_LAYER_CREATOR (ReLU, GetReLULayer) | |
| template<typename Dtype > | |
| shared_ptr< Layer< Dtype > > | GetSigmoidLayer (const LayerParameter ¶m) |
| REGISTER_LAYER_CREATOR (Sigmoid, GetSigmoidLayer) | |
| template<typename Dtype > | |
| shared_ptr< Layer< Dtype > > | GetSoftmaxLayer (const LayerParameter ¶m) |
| REGISTER_LAYER_CREATOR (Softmax, GetSoftmaxLayer) | |
| template<typename Dtype > | |
| shared_ptr< Layer< Dtype > > | GetTanHLayer (const LayerParameter ¶m) |
| REGISTER_LAYER_CREATOR (TanH, GetTanHLayer) | |
| INSTANTIATE_CLASS (AbsValLayer) | |
| REGISTER_LAYER_CLASS (AbsVal) | |
| INSTANTIATE_CLASS (AccuracyLayer) | |
| REGISTER_LAYER_CLASS (Accuracy) | |
| INSTANTIATE_CLASS (ArgMaxLayer) | |
| REGISTER_LAYER_CLASS (ArgMax) | |
| INSTANTIATE_CLASS (BaseConvolutionLayer) | |
| INSTANTIATE_CLASS (BaseDataLayer) | |
| INSTANTIATE_CLASS (BasePrefetchingDataLayer) | |
| INSTANTIATE_CLASS (BatchNormLayer) | |
| REGISTER_LAYER_CLASS (BatchNorm) | |
| INSTANTIATE_CLASS (BatchReindexLayer) | |
| REGISTER_LAYER_CLASS (BatchReindex) | |
| INSTANTIATE_CLASS (BiasLayer) | |
| REGISTER_LAYER_CLASS (Bias) | |
| INSTANTIATE_CLASS (BNLLLayer) | |
| REGISTER_LAYER_CLASS (BNLL) | |
| INSTANTIATE_CLASS (ConcatLayer) | |
| REGISTER_LAYER_CLASS (Concat) | |
| INSTANTIATE_CLASS (ContrastiveLossLayer) | |
| REGISTER_LAYER_CLASS (ContrastiveLoss) | |
| INSTANTIATE_CLASS (ConvolutionLayer) | |
| INSTANTIATE_CLASS (CropLayer) | |
| REGISTER_LAYER_CLASS (Crop) | |
| INSTANTIATE_CLASS (DataLayer) | |
| REGISTER_LAYER_CLASS (Data) | |
| INSTANTIATE_CLASS (DeconvolutionLayer) | |
| REGISTER_LAYER_CLASS (Deconvolution) | |
| INSTANTIATE_CLASS (DropoutLayer) | |
| REGISTER_LAYER_CLASS (Dropout) | |
| INSTANTIATE_CLASS (DummyDataLayer) | |
| REGISTER_LAYER_CLASS (DummyData) | |
| INSTANTIATE_CLASS (EltwiseLayer) | |
| REGISTER_LAYER_CLASS (Eltwise) | |
| INSTANTIATE_CLASS (ELULayer) | |
| REGISTER_LAYER_CLASS (ELU) | |
| INSTANTIATE_CLASS (EmbedLayer) | |
| REGISTER_LAYER_CLASS (Embed) | |
| INSTANTIATE_CLASS (EuclideanLossLayer) | |
| REGISTER_LAYER_CLASS (EuclideanLoss) | |
| INSTANTIATE_CLASS (ExpLayer) | |
| REGISTER_LAYER_CLASS (Exp) | |
| INSTANTIATE_CLASS (FilterLayer) | |
| REGISTER_LAYER_CLASS (Filter) | |
| INSTANTIATE_CLASS (FlattenLayer) | |
| REGISTER_LAYER_CLASS (Flatten) | |
| INSTANTIATE_CLASS (HDF5DataLayer) | |
| REGISTER_LAYER_CLASS (HDF5Data) | |
| INSTANTIATE_CLASS (HDF5OutputLayer) | |
| REGISTER_LAYER_CLASS (HDF5Output) | |
| INSTANTIATE_CLASS (HingeLossLayer) | |
| REGISTER_LAYER_CLASS (HingeLoss) | |
| INSTANTIATE_CLASS (Im2colLayer) | |
| REGISTER_LAYER_CLASS (Im2col) | |
| INSTANTIATE_CLASS (InfogainLossLayer) | |
| REGISTER_LAYER_CLASS (InfogainLoss) | |
| INSTANTIATE_CLASS (InnerProductLayer) | |
| REGISTER_LAYER_CLASS (InnerProduct) | |
| INSTANTIATE_CLASS (InputLayer) | |
| REGISTER_LAYER_CLASS (Input) | |
| INSTANTIATE_CLASS (LogLayer) | |
| REGISTER_LAYER_CLASS (Log) | |
| INSTANTIATE_CLASS (LossLayer) | |
| INSTANTIATE_CLASS (LRNLayer) | |
| INSTANTIATE_CLASS (LSTMLayer) | |
| REGISTER_LAYER_CLASS (LSTM) | |
| template<typename Dtype > | |
| Dtype | sigmoid (Dtype x) |
| template<typename Dtype > | |
| Dtype | tanh (Dtype x) |
| INSTANTIATE_CLASS (LSTMUnitLayer) | |
| REGISTER_LAYER_CLASS (LSTMUnit) | |
| INSTANTIATE_CLASS (MemoryDataLayer) | |
| REGISTER_LAYER_CLASS (MemoryData) | |
| INSTANTIATE_CLASS (MultinomialLogisticLossLayer) | |
| REGISTER_LAYER_CLASS (MultinomialLogisticLoss) | |
| INSTANTIATE_CLASS (MVNLayer) | |
| REGISTER_LAYER_CLASS (MVN) | |
| INSTANTIATE_CLASS (NeuronLayer) | |
| INSTANTIATE_CLASS (ParameterLayer) | |
| REGISTER_LAYER_CLASS (Parameter) | |
| INSTANTIATE_CLASS (PoolingLayer) | |
| INSTANTIATE_CLASS (PowerLayer) | |
| REGISTER_LAYER_CLASS (Power) | |
| INSTANTIATE_CLASS (PReLULayer) | |
| REGISTER_LAYER_CLASS (PReLU) | |
| INSTANTIATE_CLASS (RecurrentLayer) | |
| INSTANTIATE_CLASS (ReductionLayer) | |
| REGISTER_LAYER_CLASS (Reduction) | |
| INSTANTIATE_CLASS (ReLULayer) | |
| INSTANTIATE_CLASS (ReshapeLayer) | |
| REGISTER_LAYER_CLASS (Reshape) | |
| INSTANTIATE_CLASS (RNNLayer) | |
| REGISTER_LAYER_CLASS (RNN) | |
| INSTANTIATE_CLASS (ScaleLayer) | |
| REGISTER_LAYER_CLASS (Scale) | |
| INSTANTIATE_CLASS (SigmoidCrossEntropyLossLayer) | |
| REGISTER_LAYER_CLASS (SigmoidCrossEntropyLoss) | |
| INSTANTIATE_CLASS (SigmoidLayer) | |
| INSTANTIATE_CLASS (SilenceLayer) | |
| REGISTER_LAYER_CLASS (Silence) | |
| INSTANTIATE_CLASS (SliceLayer) | |
| REGISTER_LAYER_CLASS (Slice) | |
| INSTANTIATE_CLASS (SoftmaxLayer) | |
| INSTANTIATE_CLASS (SoftmaxWithLossLayer) | |
| REGISTER_LAYER_CLASS (SoftmaxWithLoss) | |
| INSTANTIATE_CLASS (SplitLayer) | |
| REGISTER_LAYER_CLASS (Split) | |
| INSTANTIATE_CLASS (SPPLayer) | |
| REGISTER_LAYER_CLASS (SPP) | |
| INSTANTIATE_CLASS (TanHLayer) | |
| INSTANTIATE_CLASS (ThresholdLayer) | |
| REGISTER_LAYER_CLASS (Threshold) | |
| INSTANTIATE_CLASS (TileLayer) | |
| REGISTER_LAYER_CLASS (Tile) | |
| INSTANTIATE_CLASS (Net) | |
| INSTANTIATE_CLASS (Solver) | |
| template<typename Dtype > | |
| void | adadelta_update_gpu (int N, Dtype *g, Dtype *h, Dtype *h2, Dtype momentum, Dtype delta, Dtype local_rate) |
| INSTANTIATE_CLASS (AdaDeltaSolver) | |
| REGISTER_SOLVER_CLASS (AdaDelta) | |
| template<typename Dtype > | |
| void | adagrad_update_gpu (int N, Dtype *g, Dtype *h, Dtype delta, Dtype local_rate) |
| INSTANTIATE_CLASS (AdaGradSolver) | |
| REGISTER_SOLVER_CLASS (AdaGrad) | |
| template<typename Dtype > | |
| void | adam_update_gpu (int N, Dtype *g, Dtype *m, Dtype *v, Dtype beta1, Dtype beta2, Dtype eps_hat, Dtype corrected_local_rate) |
| INSTANTIATE_CLASS (AdamSolver) | |
| REGISTER_SOLVER_CLASS (Adam) | |
| template<typename Dtype > | |
| void | nesterov_update_gpu (int N, Dtype *g, Dtype *h, Dtype momentum, Dtype local_rate) |
| INSTANTIATE_CLASS (NesterovSolver) | |
| REGISTER_SOLVER_CLASS (Nesterov) | |
| template<typename Dtype > | |
| void | rmsprop_update_gpu (int N, Dtype *g, Dtype *h, Dtype rms_decay, Dtype delta, Dtype local_rate) |
| INSTANTIATE_CLASS (RMSPropSolver) | |
| REGISTER_SOLVER_CLASS (RMSProp) | |
| template<typename Dtype > | |
| void | sgd_update_gpu (int N, Dtype *g, Dtype *h, Dtype momentum, Dtype local_rate) |
| INSTANTIATE_CLASS (SGDSolver) | |
| REGISTER_SOLVER_CLASS (SGD) | |
| template<> | |
| void | hdf5_load_nd_dataset< float > (hid_t file_id, const char *dataset_name_, int min_dim, int max_dim, Blob< float > *blob, bool reshape) |
| template<> | |
| void | hdf5_load_nd_dataset< double > (hid_t file_id, const char *dataset_name_, int min_dim, int max_dim, Blob< double > *blob, bool reshape) |
| template<> | |
| void | hdf5_save_nd_dataset< float > (const hid_t file_id, const string &dataset_name, const Blob< float > &blob, bool write_diff) |
| template<> | |
| void | hdf5_save_nd_dataset< double > (hid_t file_id, const string &dataset_name, const Blob< double > &blob, bool write_diff) |
| bool | is_a_ge_zero_and_a_lt_b (int a, int b) |
| template void | im2col_cpu< float > (const float *data_im, const int channels, const int height, const int width, const int kernel_h, const int kernel_w, const int pad_h, const int pad_w, const int stride_h, const int stride_w, const int dilation_h, const int dilation_w, float *data_col) |
| template void | im2col_cpu< double > (const double *data_im, const int channels, const int height, const int width, const int kernel_h, const int kernel_w, const int pad_h, const int pad_w, const int stride_h, const int stride_w, const int dilation_h, const int dilation_w, double *data_col) |
| template<typename Dtype > | |
| void | im2col_nd_core_cpu (const Dtype *data_input, const bool im2col, const int num_spatial_axes, const int *im_shape, const int *col_shape, const int *kernel_shape, const int *pad, const int *stride, const int *dilation, Dtype *data_output) |
| template void | im2col_nd_cpu< float > (const float *data_im, const int num_spatial_axes, const int *im_shape, const int *col_shape, const int *kernel_shape, const int *pad, const int *stride, const int *dilation, float *data_col) |
| template void | im2col_nd_cpu< double > (const double *data_im, const int num_spatial_axes, const int *im_shape, const int *col_shape, const int *kernel_shape, const int *pad, const int *stride, const int *dilation, double *data_col) |
| template void | col2im_cpu< float > (const float *data_col, const int channels, const int height, const int width, const int kernel_h, const int kernel_w, const int pad_h, const int pad_w, const int stride_h, const int stride_w, const int dilation_h, const int dilation_w, float *data_im) |
| template void | col2im_cpu< double > (const double *data_col, const int channels, const int height, const int width, const int kernel_h, const int kernel_w, const int pad_h, const int pad_w, const int stride_h, const int stride_w, const int dilation_h, const int dilation_w, double *data_im) |
| template void | col2im_nd_cpu< float > (const float *data_col, const int num_spatial_axes, const int *im_shape, const int *col_shape, const int *kernel_shape, const int *pad, const int *stride, const int *dilation, float *data_im) |
| template void | col2im_nd_cpu< double > (const double *data_col, const int num_spatial_axes, const int *im_shape, const int *col_shape, const int *kernel_shape, const int *pad, const int *stride, const int *dilation, double *data_im) |
| template<> | |
| void | caffe_cpu_gemm< float > (const CBLAS_TRANSPOSE TransA, const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K, const float alpha, const float *A, const float *B, const float beta, float *C) |
| template<> | |
| void | caffe_cpu_gemm< double > (const CBLAS_TRANSPOSE TransA, const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K, const double alpha, const double *A, const double *B, const double beta, double *C) |
| template<> | |
| void | caffe_cpu_gemv< float > (const CBLAS_TRANSPOSE TransA, const int M, const int N, const float alpha, const float *A, const float *x, const float beta, float *y) |
| template<> | |
| void | caffe_cpu_gemv< double > (const CBLAS_TRANSPOSE TransA, const int M, const int N, const double alpha, const double *A, const double *x, const double beta, double *y) |
| template<> | |
| void | caffe_axpy< float > (const int N, const float alpha, const float *X, float *Y) |
| template<> | |
| void | caffe_axpy< double > (const int N, const double alpha, const double *X, double *Y) |
| template void | caffe_set< int > (const int N, const int alpha, int *Y) |
| template void | caffe_set< float > (const int N, const float alpha, float *Y) |
| template void | caffe_set< double > (const int N, const double alpha, double *Y) |
| template<> | |
| void | caffe_add_scalar (const int N, const float alpha, float *Y) |
| template<> | |
| void | caffe_add_scalar (const int N, const double alpha, double *Y) |
| template void | caffe_copy< int > (const int N, const int *X, int *Y) |
| template void | caffe_copy< unsigned int > (const int N, const unsigned int *X, unsigned int *Y) |
| template void | caffe_copy< float > (const int N, const float *X, float *Y) |
| template void | caffe_copy< double > (const int N, const double *X, double *Y) |
| template<> | |
| void | caffe_scal< float > (const int N, const float alpha, float *X) |
| template<> | |
| void | caffe_scal< double > (const int N, const double alpha, double *X) |
| template<> | |
| void | caffe_cpu_axpby< float > (const int N, const float alpha, const float *X, const float beta, float *Y) |
| template<> | |
| void | caffe_cpu_axpby< double > (const int N, const double alpha, const double *X, const double beta, double *Y) |
| template<> | |
| void | caffe_add< float > (const int n, const float *a, const float *b, float *y) |
| template<> | |
| void | caffe_add< double > (const int n, const double *a, const double *b, double *y) |
| template<> | |
| void | caffe_sub< float > (const int n, const float *a, const float *b, float *y) |
| template<> | |
| void | caffe_sub< double > (const int n, const double *a, const double *b, double *y) |
| template<> | |
| void | caffe_mul< float > (const int n, const float *a, const float *b, float *y) |
| template<> | |
| void | caffe_mul< double > (const int n, const double *a, const double *b, double *y) |
| template<> | |
| void | caffe_div< float > (const int n, const float *a, const float *b, float *y) |
| template<> | |
| void | caffe_div< double > (const int n, const double *a, const double *b, double *y) |
| template<> | |
| void | caffe_powx< float > (const int n, const float *a, const float b, float *y) |
| template<> | |
| void | caffe_powx< double > (const int n, const double *a, const double b, double *y) |
| template<> | |
| void | caffe_sqr< float > (const int n, const float *a, float *y) |
| template<> | |
| void | caffe_sqr< double > (const int n, const double *a, double *y) |
| template<> | |
| void | caffe_sqrt< float > (const int n, const float *a, float *y) |
| template<> | |
| void | caffe_sqrt< double > (const int n, const double *a, double *y) |
| template<> | |
| void | caffe_exp< float > (const int n, const float *a, float *y) |
| template<> | |
| void | caffe_exp< double > (const int n, const double *a, double *y) |
| template<> | |
| void | caffe_log< float > (const int n, const float *a, float *y) |
| template<> | |
| void | caffe_log< double > (const int n, const double *a, double *y) |
| template<> | |
| void | caffe_abs< float > (const int n, const float *a, float *y) |
| template<> | |
| void | caffe_abs< double > (const int n, const double *a, double *y) |
| template float | caffe_nextafter (const float b) |
| template double | caffe_nextafter (const double b) |
| template void | caffe_rng_uniform< float > (const int n, const float a, const float b, float *r) |
| template void | caffe_rng_uniform< double > (const int n, const double a, const double b, double *r) |
| template void | caffe_rng_gaussian< float > (const int n, const float mu, const float sigma, float *r) |
| template void | caffe_rng_gaussian< double > (const int n, const double mu, const double sigma, double *r) |
| template void | caffe_rng_bernoulli< double > (const int n, const double p, int *r) |
| template void | caffe_rng_bernoulli< float > (const int n, const float p, int *r) |
| template void | caffe_rng_bernoulli< double > (const int n, const double p, unsigned int *r) |
| template void | caffe_rng_bernoulli< float > (const int n, const float p, unsigned int *r) |
| template<> | |
| float | caffe_cpu_strided_dot< float > (const int n, const float *x, const int incx, const float *y, const int incy) |
| template<> | |
| double | caffe_cpu_strided_dot< double > (const int n, const double *x, const int incx, const double *y, const int incy) |
| template float | caffe_cpu_dot< float > (const int n, const float *x, const float *y) |
| template double | caffe_cpu_dot< double > (const int n, const double *x, const double *y) |
| template<> | |
| float | caffe_cpu_asum< float > (const int n, const float *x) |
| template<> | |
| double | caffe_cpu_asum< double > (const int n, const double *x) |
| template<> | |
| void | caffe_cpu_scale< float > (const int n, const float alpha, const float *x, float *y) |
| template<> | |
| void | caffe_cpu_scale< double > (const int n, const double alpha, const double *x, double *y) |
Variables | |
| const float | kLOG_THRESHOLD = 1e-20 |
| const int | CAFFE_CUDA_NUM_THREADS = 512 |
| const Dtype | alpha |
| const Dtype const Dtype * | x |
| const Dtype const Dtype Dtype * | y |
| const float | kBNLL_THRESHOLD = 50. |
Detailed Description
A layer factory that allows one to register layers. During runtime, registered layers can be called by passing a LayerParameter protobuffer to the CreateLayer function:
A solver factory that allows one to register solvers, similar to layer factory. During runtime, registered solvers could be called by passing a SolverParameter protobuffer to the CreateSolver function:
LayerRegistry<Dtype>::CreateLayer(param);
There are two ways to register a layer. Assuming that we have a layer like:
template <typename dtype>=""> class MyAwesomeLayer : public Layer<Dtype> { // your implementations };
and its type is its C++ class name, but without the "Layer" at the end ("MyAwesomeLayer" -> "MyAwesome").
If the layer is going to be created simply by its constructor, in your c++ file, add the following line:
REGISTER_LAYER_CLASS(MyAwesome);
Or, if the layer is going to be created by another creator function, in the format of:
template <typename dtype>=""> Layer<Dtype*> GetMyAwesomeLayer(const LayerParameter& param) { // your implementation }
(for example, when your layer has multiple backends, see GetConvolutionLayer for a use case), then you can register the creator function instead, like
REGISTER_LAYER_CREATOR(MyAwesome, GetMyAwesomeLayer)
Note that each layer type should only be registered once.
SolverRegistry<Dtype>::CreateSolver(param);
There are two ways to register a solver. Assuming that we have a solver like:
template <typename dtype>=""> class MyAwesomeSolver : public Solver<Dtype> { // your implementations };
and its type is its C++ class name, but without the "Solver" at the end ("MyAwesomeSolver" -> "MyAwesome").
If the solver is going to be created simply by its constructor, in your C++ file, add the following line:
REGISTER_SOLVER_CLASS(MyAwesome);
Or, if the solver is going to be created by another creator function, in the format of:
template <typename dtype>=""> Solver<Dtype*> GetMyAwesomeSolver(const SolverParameter& param) { // your implementation }
then you can register the creator function instead, like
REGISTER_SOLVER_CREATOR(MyAwesome, GetMyAwesomeSolver)
Note that each solver type should only be registered once.
Function Documentation
◆ GetFiller()
| Filler<Dtype>* caffe::GetFiller | ( | const FillerParameter & | param | ) |
Get a specific filler from the specification given in FillerParameter.
Ideally this would be replaced by a factory pattern, but we will leave it this way for now.
